I’m glad to hear that Yayzi is a passion project, and that you’re invested in the idea of running a better ISP. I also appreciate that this migration is a stressful project for the people working on it, and I’m happy that you communicate with customers in the open like this, saving me from needing to waste both of our time raising tickets for issues that I can quickly see that others are having by checking here. Most ISPs would never be willing to take the risk of running a public customer forum, and it’s a real selling point for Yayzi that you’re doing this.
That said - I’ve been checking in here for updates for the past few days, and I think there’s a disconnect around customer expectations, acceptable service levels, and communications. There’s a lot of users posting their relatable, but brief, frustrations lately - but I have a bit of downtime while I wait for my connection to be usable for work again, and text is one of the few things that I can use reliably right now, so forgive me for going a little long here. Hopefully I can give a bit of context and explain some of the frustrations that might be feeling unheard.
I work from home in a data-heavy job, so I chose Yayzi for one reason - I want the best internet connection I get. My commercial options are limited and impractical, but Yayzi has the fastest speeds available, and you pitch yourselves towards remote working, which I figured implied a focus on stability - even if the Terms & Conditions don’t really seem to specify any floor to the level of service.
The initial migration email on the 4th mentioned the potential for short dropouts of a few minutes. I can live with that, that sort of thing can happen with any ISP. The network upgrade email on the 6th warned of a speed reduction to 250Mb/s, and occasional latency spikes. That’s a bit annoying, I have a big project this week, and it might slow me down, but I can put up with running at 10% speed for a few days.
Then on Sunday evening the dropouts started, but instead of the brief dropouts mentioned in the email, it’s a series of extended outages with intermittent routing behaviour in between, in a manner that at least gave the impression of “testing in production”. I understand now that this was an error introduced during a rushed deployment - but only because I came here to see what had been going on. I’m feeling pretty frustrated at this point, I had to stay up late to try to catch up on the work I couldn’t get done in the evening, and I’m just hoping that Yayzi take some time to step back for a retro, and take extra care to avoid a repetition.
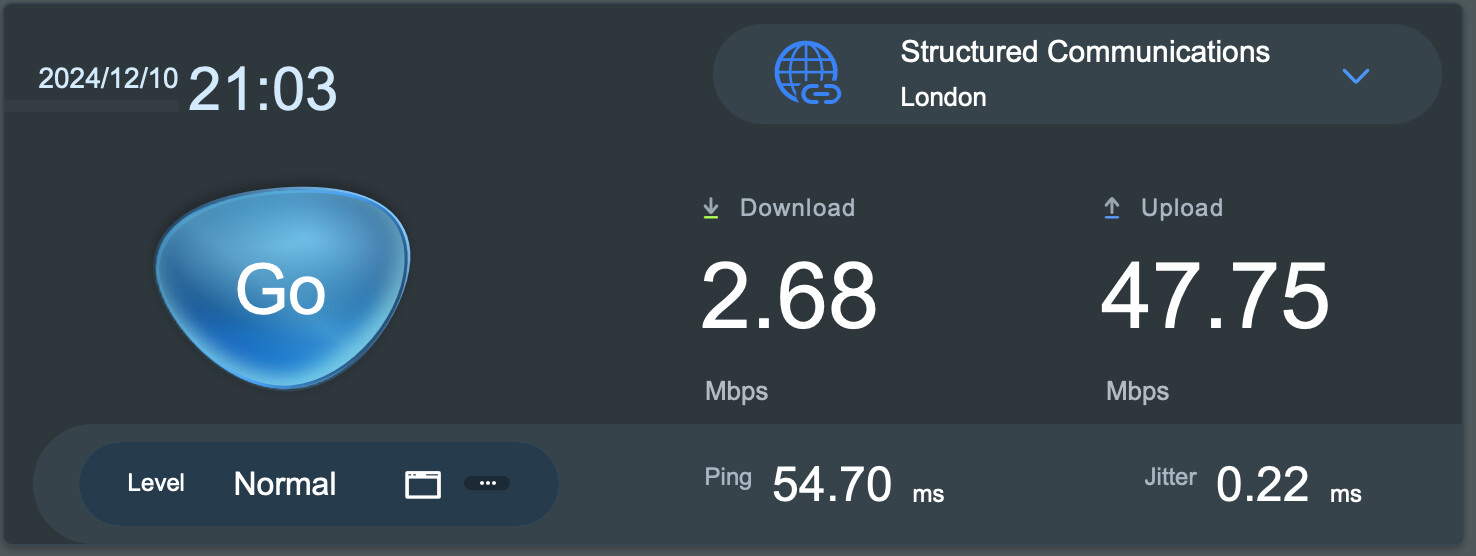
Then, yesterday, I find my download speed has dropped to around 2Mb/s, less than a thousandth what it should be. At this point, it’s no longer useable for anything beyond basic web browsing. Checking in here again, there’s understandably a lot of frustrated customers looking for answers, and a lot of confusion around what we should be expecting to see from the migration, versus what is an unexpected issue. I saw a lot of responses from Yayzi, but the key message seemed to be “we warned there would be issues during the migration, but it will be worth it when it’s done”. I eventually found a post saying that the ~2Mbps speed isn’t expected and is being looked in to.
Yet here we are today, and we’re back down to 2Mbps again. Given that yesterday’s glacial speeds weren’t intentional after all, I assumed things would have gone one of two ways - either the cause of this issue was identified and mitigated, and the migration could continue, or the migration process would be paused until a workaround can be found, or rescheduled to a slower rollout using early hours.
What I, and I think some of the other users here have been looking for, is some level of clarification and commitment around the service levels we can expect to receive. There’s an enormous practical difference between customers getting 10% of their contract speed, and 0.1%. Occasional spikes of latency are different to a consistently elevated latency, and occasional short outages of a few minutes are very different to prolonged outages spanning hours. The only official comms I’ve seen from Yayzi over this period is the “Good News” email with the apology for hiccups and the LLM cheese.
I’m still not clear on exactly what level of service Yayzi is actually aiming to deliver at the moment. Yesterday, it seemed that the 2Mb/s wasn’t considered an expected or acceptable level of service. Today, it’s looking like this might just be considered the new normal for the remainder of the migration window, and that the original comms about the reduction to around 250Mb/s are supposed to cover this.
I know this migration won’t last forever, and I’m sure you’re confident that after Wednesday you’ll be delivering a consistently high level of service again and there’ll be nothing to worry about. I understand that I made a tradeoff and took a risk moving from a slower business ISP with an SLA to a faster residential one without guarantees. But what I’d expected, or at least hoped, is that Yayzi would at least have internal SLOs for speed, performance, and stability, and that these metrics are considered when rolling out changes.
My understanding of the situation right now is that the bandwidth throttling applied during yesterday evening’s migration turned out to be much more aggressive than Yayzi expected when you sent out the initial comms, and that this can’t just be mitigated with the help of CityFibre, or staggering the migration rollout over a longer period. If so - then it’s hard to escape the conclusion that Yayzi were aware that continuing with migrations today would cause the speeds to drop to unusable levels for another evening, but went ahead with it anyway to finish the migration on schedule. Am I right in my conclusion here? If not, could you give some background as to why the issue reoccurred unexpectedly, and whether there’s a plan to address it? If so - then I’d be a little worried that so soon after experiencing an incident caused by a rushed deployment, you’d choose to risk further outages in order to meet an internal deadline.
Ultimately, what I’d really like to see out Yayzi, is some sort of definition around what’s considered an outage, acceptably versus unacceptably degraded service, and what objectives Yayzi has for maintaining these. I think the majority of threads from frustrated users here are caused by the gulf between the expectations set in the initial migration email, and the reality of the service that users are experiencing. It still feels ambiguous to me whether the current speeds are something you’re actively working to fix, or just a change the expected impact of migration that hasn’t been communicated.
Even if the answer is just “the migration impact is much worse than expected for users, but we just can’t justify the extra time / effort to mitigate a few days of outages” - it’s not the choice I’d hope that you’d make, but I’d at least value the forthright explanation and effort to align expectations.